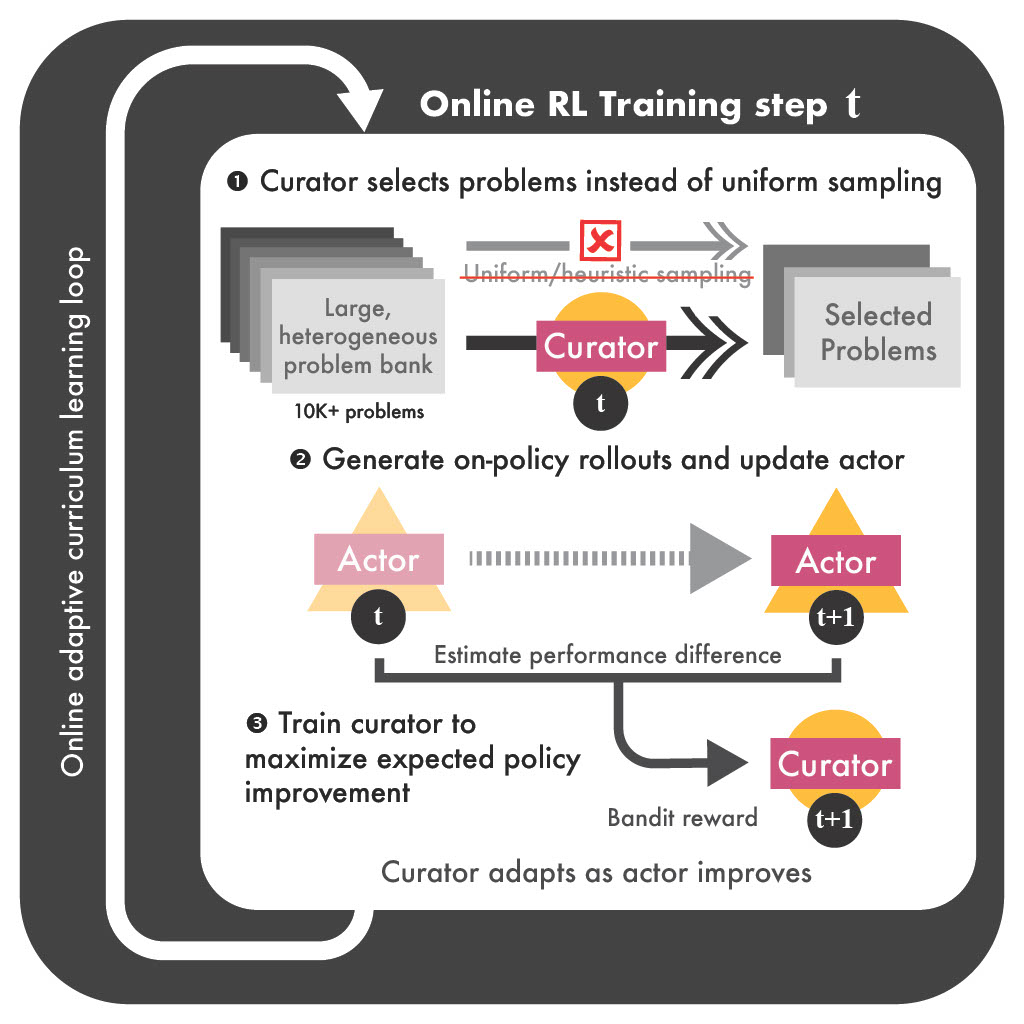
A learned neural curator jointly trained with the actor to dynamically select problems from massive datasets. Non-stationary stochastic bandit formulation with OSMD-based updates and regret guarantees; up to 30% performance gains and 80% faster convergence across challenging reasoning benchmarks.
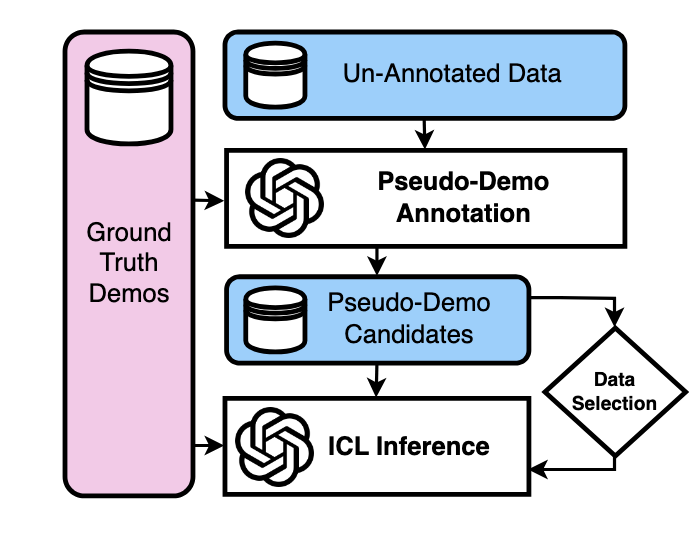
Semi-supervised ICL framework: confidence-filtered pseudo-demonstrations, no ground-truth labels required, that scales to 1,000+ demonstrations and outperforms standard ICL across zero-shot, few-shot, and many-shot settings. IterPSD further improves quality via iterative refinement and curriculum pseudo-labeling; up to 6.8% gains on classification tasks across 16 benchmarks.
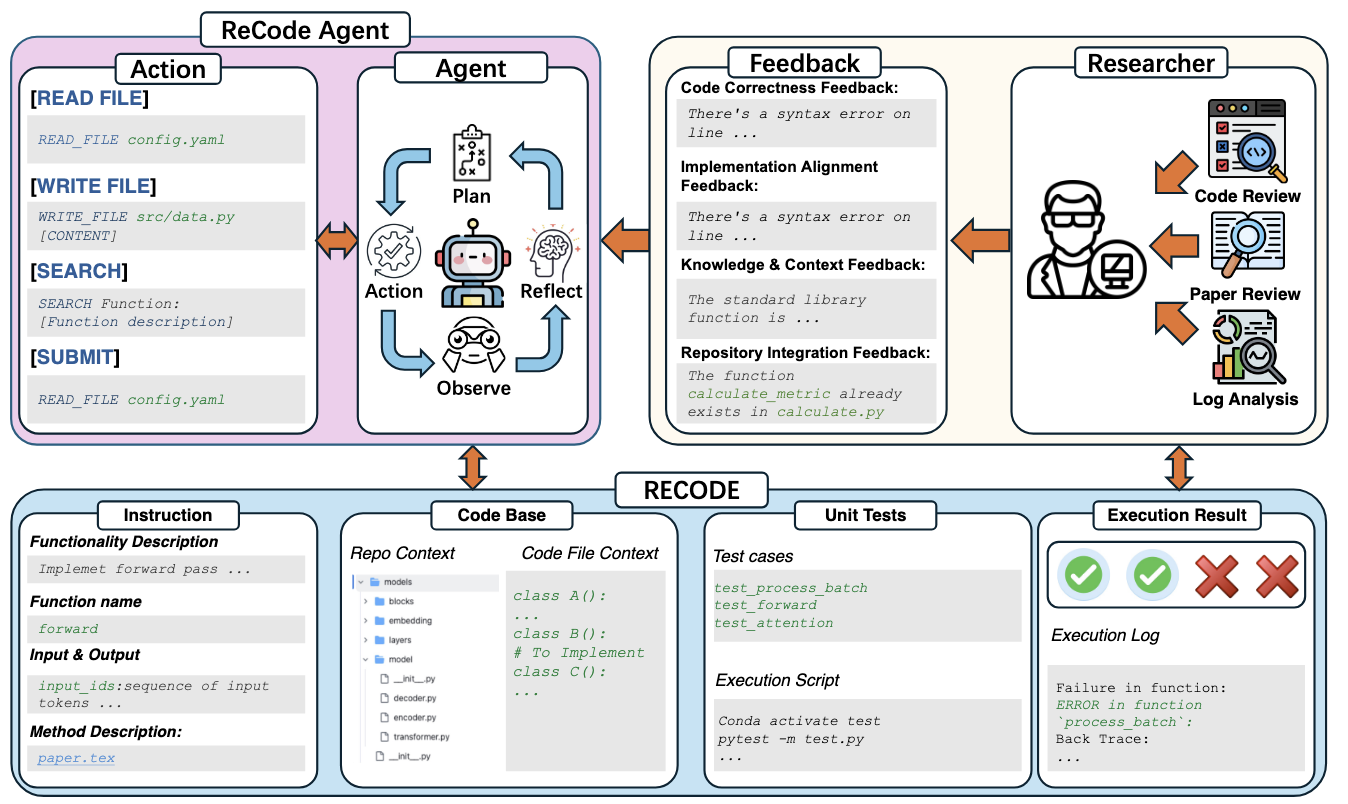
102 PhD-level repository tasks from real research papers — structured instructions, unit tests, and a five-level feedback hierarchy simulating realistic researcher–agent collaboration. Experiments across GPT-5, Claude-Sonnet-4, DeepSeek-V3.1, and Gemini 2.5 show even minimal diagnostic feedback nearly doubles pass rates; dominant failure modes are paper misinterpretation and missing domain knowledge, not syntax errors.
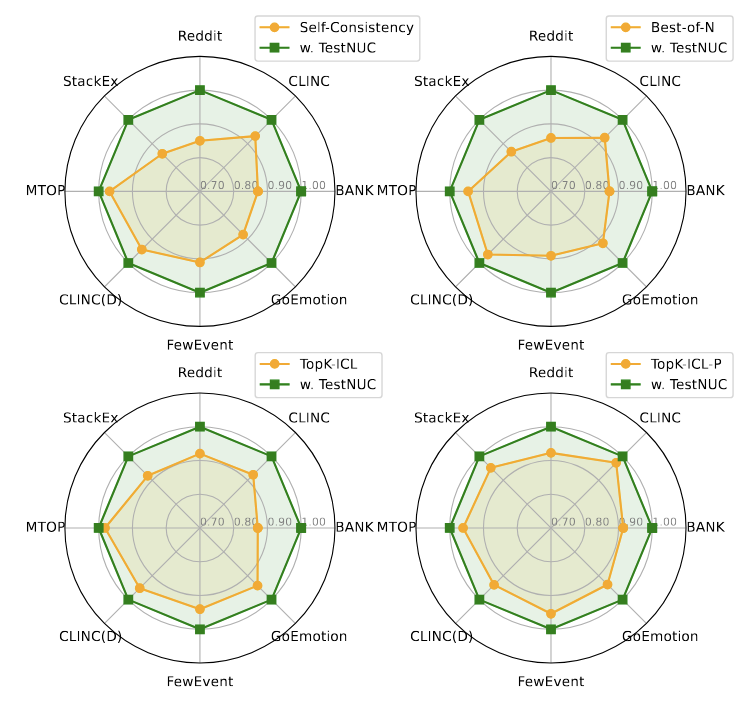
TestNUC boosts LLM classification at inference time by majority-voting over predictions on semantically similar unlabeled neighbors. Outperforms self-consistency by ~6–10% across 8 datasets and 4 models; scales linearly in compute.